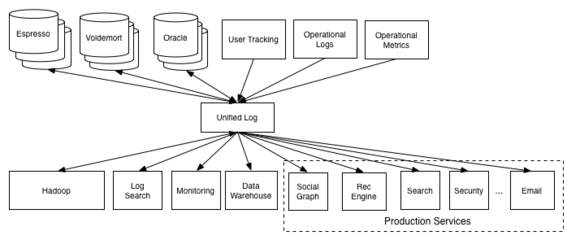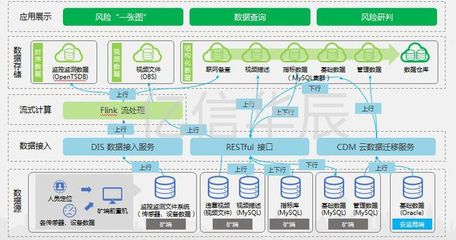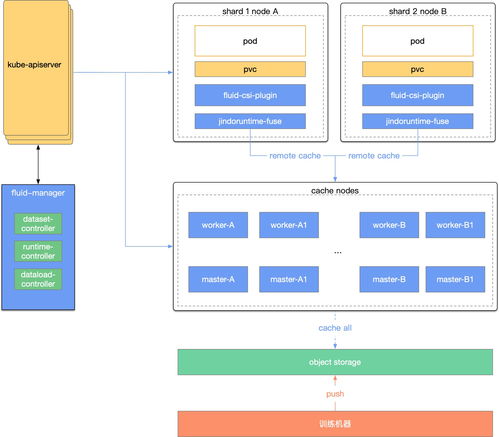
隨著人工智能技術(shù)的快速發(fā)展,數(shù)據(jù)處理和存儲服務(wù)在現(xiàn)代企業(yè)架構(gòu)中扮演著至關(guān)重要的角色。作業(yè)幫作為國內(nèi)領(lǐng)先的教育科技公司,其檢索服務(wù)每天需要處理海量的用戶查詢和內(nèi)容匹配請求。為了提升服務(wù)性能和資源利用率,作業(yè)幫選擇了基于Fluid的計算存儲分離架構(gòu),實現(xiàn)了數(shù)據(jù)處理與存儲服務(wù)的深度優(yōu)化。
一、背景與挑戰(zhàn)
作業(yè)幫檢索服務(wù)作為核心業(yè)務(wù)模塊,需要快速響應(yīng)用戶的搜索請求,并提供準(zhǔn)確的內(nèi)容推薦。在傳統(tǒng)架構(gòu)中,計算節(jié)點和存儲節(jié)點緊密耦合,導(dǎo)致了以下問題:
- 資源分配不均衡:計算密集型任務(wù)和存儲密集型任務(wù)爭奪同一資源池,導(dǎo)致系統(tǒng)瓶頸頻現(xiàn)。
- 擴(kuò)展性受限:數(shù)據(jù)量激增時,難以靈活擴(kuò)展計算或存儲資源。
- 運維成本高:數(shù)據(jù)遷移和節(jié)點維護(hù)操作復(fù)雜,影響服務(wù)可用性。
二、Fluid計算存儲分離架構(gòu)的優(yōu)勢
Fluid是云原生場景下的開源項目,專注于大數(shù)據(jù)和AI場景中的數(shù)據(jù)編排和加速。作業(yè)幫通過引入Fluid,實現(xiàn)了以下關(guān)鍵優(yōu)化:
- 解耦計算與存儲:計算節(jié)點和存儲節(jié)點獨立擴(kuò)展,提升了系統(tǒng)的靈活性和資源利用率。
- 數(shù)據(jù)本地化加速:通過緩存和預(yù)加載機制,F(xiàn)luid將常用數(shù)據(jù)緩存到計算節(jié)點本地,大幅降低了數(shù)據(jù)訪問延遲。
- 統(tǒng)一數(shù)據(jù)管理:Fluid提供了統(tǒng)一的數(shù)據(jù)抽象層,支持多種存儲后端(如HDFS、OSS、Ceph等),簡化了數(shù)據(jù)運維流程。
三、實踐方案與實施步驟
作業(yè)幫在檢索服務(wù)中實施Fluid架構(gòu)的主要步驟包括:
- 環(huán)境準(zhǔn)備:部署Kubernetes集群,并安裝Fluid組件。
- 數(shù)據(jù)集定義:通過Fluid的Dataset資源定義需要加速的數(shù)據(jù)集,并關(guān)聯(lián)底層存儲系統(tǒng)。
- 緩存策略配置:根據(jù)業(yè)務(wù)需求設(shè)置緩存大小、預(yù)熱策略和數(shù)據(jù)淘汰規(guī)則。
- 計算任務(wù)調(diào)度:利用Fluid的Runtime(如AlluxioRuntime)將數(shù)據(jù)緩存到計算節(jié)點,并通過親和性調(diào)度確保任務(wù)在數(shù)據(jù)本地節(jié)點執(zhí)行。
四、成果與收益
通過基于Fluid的計算存儲分離實踐,作業(yè)幫檢索服務(wù)取得了顯著成效:
- 性能提升:數(shù)據(jù)訪問延遲降低約40%,檢索服務(wù)的平均響應(yīng)時間縮短了30%。
- 成本優(yōu)化:存儲和計算資源獨立擴(kuò)展,避免了過度配置,資源利用率提升25%以上。
- 運維簡化:數(shù)據(jù)管理操作自動化,減少了人工干預(yù),系統(tǒng)穩(wěn)定性顯著增強。
五、未來展望
未來,作業(yè)幫計劃進(jìn)一步探索Fluid在更多業(yè)務(wù)場景中的應(yīng)用,例如結(jié)合AI訓(xùn)練任務(wù)和多租戶數(shù)據(jù)隔離。同時,團(tuán)隊將持續(xù)優(yōu)化緩存策略和數(shù)據(jù)預(yù)取算法,以應(yīng)對日益增長的數(shù)據(jù)處理需求。
基于Fluid的計算存儲分離架構(gòu)為作業(yè)幫檢索服務(wù)的數(shù)據(jù)處理和存儲提供了高效、靈活的解決方案。這一實踐不僅提升了系統(tǒng)性能,還為后續(xù)的技術(shù)演進(jìn)奠定了堅實基礎(chǔ)。